
Lua 5.4 源码
前言
基本架构

以下是Lua 5.3.5源码在src目录下的代码结构整理,分为三大部分:虚拟机核心功能、源代码解析和预编译、内嵌库。每个部分包含核心文件及其作用说明,便于快速理解Lua源码的组织架构。
一、虚拟机核心功能部分
负责Lua虚拟机的核心运行机制,包括内存管理、垃圾回收、字节码执行等。
| 文件 | 作用 |
|---|---|
lapi.c |
提供C语言接口,实现Lua与C的交互 |
ldebug.c |
Debug接口,支持断点、堆栈跟踪等调试功能 |
ldo.c |
管理函数调用栈和协程栈 |
lfunc.c |
管理函数原型(Proto)和闭包(Closure)的创建与销毁 |
lgc.c |
垃圾回收机制(GC),包括标记-清除算法和分代回收策略 |
lmem.c |
内存管理接口,负责动态内存分配与释放 |
lobject.c |
对象操作函数,处理Lua中所有数据类型的通用操作(如类型判断、值转换) |
lopcodes.c |
定义虚拟机字节码的操作码(OpCode)及其编码格式 |
lstate.c |
管理全局状态机(lua_State),维护运行时环境、注册表等全局信息 |
lstring.c |
实现字符串池(String Interning),避免重复字符串的内存开销 |
ltable.c |
表(Table)的实现,包括哈希表和数组的混合结构及元表操作 |
ltm.c |
元方法(Metamethod)的处理,如__index、__add等运算符重载 |
lvm.c |
虚拟机核心,解释执行字节码指令 |
lzio.c |
输入流接口,支持从文件、字符串等源读取数据 |
lua.c |
Lua可执行程序的入口(main函数),提供命令行交互环境 |
二、源代码解析和预编译部分
将Lua脚本编译为字节码,支持序列化与反序列化。
| 文件 | 作用 |
|---|---|
lcode.c |
代码生成器,将抽象语法树(AST)转换为虚拟机字节码 |
ldump.c |
序列化预编译的Lua字节码,生成.luac文件 |
llex.c |
词法分析器,将源代码分割为Token(如标识符、关键字、数字等) |
lparser.c |
语法分析器,构建抽象语法树(AST)并校验语义合法性 |
lundump.c |
还原预编译的字节码,加载.luac文件到内存 |
三、内嵌库部分
提供Lua标准库的实现,支持基础功能扩展。
| 文件 | 作用 |
|---|---|
lauxlib.c |
辅助函数库,简化C模块开发(如参数检查、内存错误处理) |
lbaselib.c |
基础库,实现print()、assert()、error()等核心函数 |
ldblib.c |
Debug库,提供debug.traceback()、debug.getlocal()等调试工具 |
linit.c |
内嵌库初始化,注册所有标准库到全局环境 |
liolib.c |
I/O库,实现文件读写(io.open())、流操作(io.stdin)等 |
lmathlib.c |
数学库,提供math.sin()、math.random()等数学函数 |
loadlib.c |
动态扩展库管理,支持require()加载C模块 |
loslib.c |
操作系统库,封装os.time()、os.execute()等系统调用 |
lstrlib.c |
字符串库,支持模式匹配、格式化(string.match()、string.format()) |
ltablib.c |
表处理库,实现table.insert()、table.sort()等操作 |
总结
Lua源码设计特点:
- 模块化清晰:三个部分职责分离,虚拟机核心、编译器、标准库各自独立,便于维护。
- 轻量高效:总代码约1万行,核心虚拟机(
lvm.c、lstate.c)和编译器(lparser.c、lcode.c)占主体。 - 可扩展性强:通过
lauxlib.c和loadlib.c支持C模块动态加载,内嵌库可裁剪。
对于源码学习建议:
- 从入口开始:优先阅读
lua.c的main函数,理解解释器初始化流程。- 深入虚拟机:结合
lopcodes.c的字节码定义,分析lvm.c中的指令执行逻辑。- 实践调试:通过修改
ldebug.c添加自定义调试信息,观察运行时行为。
Lua的精简架构使其成为学习编译器与虚拟机设计的优秀范本,建议按“核心→编译器→库”的顺序逐步深入。
GC
版本发展
Lua在5.0版本的时候,使⽤的是“双⾊标记清除算法”,垃圾回收过程⼀旦开始就需要等待全部完成才能继续其它流程,此时如果待处理的对象很多,则会卡顿至完成处理完所有对象,极大影响程序性能。
Lua升级到5.1版本后,算法发生了很大的变化,算法优化成了“三⾊标记清除算法”, 后续的版本都⼀直采⽤该算法。垃圾回收过程可以增量式的分步执⾏,不再需要等待全部执⾏完毕再执⾏后⾯的其它程序流程。但这个算法也有⼀定局限性,虽然垃圾回收过程可 以分步执⾏,但这是⼀个由前往后的过程,意味着不能在处理到中间的时候⼜返回去前⾯处理新的对象,新加⼊的内存垃圾 ⼀定得等到本次垃圾回收过程处理完所有旧对象,下⼀次垃圾回收机制重新开始才能被处理到,所以及时性不够强。
Lua升级到5.1版本后,除了⽀持“三⾊标记清除算法”,还新增了⼀个可选择的垃圾回收算法类型“分代式算法”,该算法把对象按年龄(被垃圾回收处理的次数)分为年轻⼀代和⽼⼀代。对年轻的对象会有更多的“关爱”,会有更及时的响应,所以能解决“三⾊标记清除算法”的及时性问题。但是“分代算法”也有其局限性,就是会有⽼⼀代对象的内存堆积和残留。所以 在实际使⽤中,使⽤者可根据⾃身需求确定使⽤哪⼀种垃圾 回收算法或者混合使⽤。
数据结构
Lua有两种垃圾回收算法,分别为增量式标记清除算法与分代式算法,见源码***《lstate.h》***中的枚举定义:

我们常说的GC即代表GarbageCollection,译为垃圾回收。见上图英文,KGC则代表Kindofgarbagecollection,翻译为垃圾回收类型,Lua中分为两种垃圾回收算法类型:
1)***KGC_INC:incrementalgc***,增量式算法,实现方式即为我们说到的三色标记清除算法;
2)***KGC_GEN:genrationalgc***,分代式算法。
默认的垃圾回收算法类型
若开发人员没有设置Lua的垃圾回收算法类型,则增量式三色标记清除算法类型为默认垃圾回收类型,见源码***《lstate.c》中lua_newstate***:
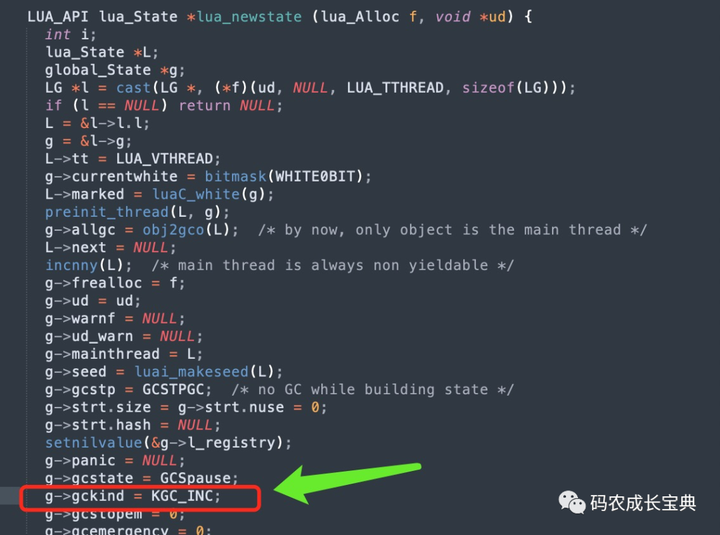
此函数用于创建Lua运行状态机,可理解为Lua主线程运行环境的初始化,红框部分代码g->gckind=KGC_INC即表示默认使用增量式算法。
使用默认的增量式三色标记清除算法可满足大多数Lua项目的需求,所以相对于分代式算法,大家更应该加强理解这个三色标记清除算法。
垃圾回收的基础单位-GCObject
接下来,我们就真正开始讲解Lua对象在内存中的组织与遍历形式。在Lua中,我们上层开发者使用的对象其实都是TValue类型的对象,然后这些TValue对象有些会直接存储有意义数据,有些则通过指针指向一个需要被垃圾回收机制所管理的对象,而这些被管理的对象,他们有着共同的特点,就是他们都是从GCObject类继承的子类型。
真正讲解GCObject之前,我们先回顾一下TValue类型对象,见源码***《lobject.h》TValue***的结构体定义:
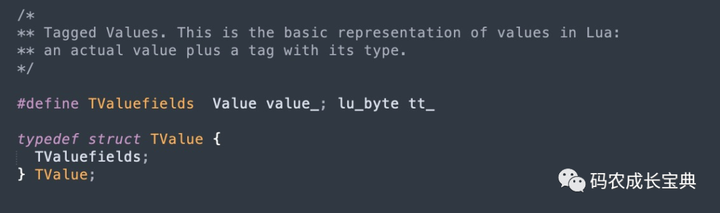
上图可知,TValue中声明了一个TValuefields宏字段,而TValuefields宏展开即为一个Value类型对象与lu_byte一个字节大小的类型标记tt_(typetag)字段,我们讲解基础类型课程的时候知道**tt_**就是用来表示并区分不同基础类型的。
接下来,我们重点看源码***《lobject.h》Value***对象的定义:
